 深入理解 go Mutex
深入理解 go Mutex
在我们的日常开发中,总会有时候需要对一些变量做并发读写,比如 web 应用在同时接到多个请求之后, 需要对一些资源做初始化,而这些资源可能是只需要初始化一次的,而不是每一个 http 请求都初始化, 在这种情况下,我们需要限制只能一个协程来做初始化的操作,比如初始化数据库连接等, 这个时候,我们就需要有一种机制,可以限制只有一个协程来执行这些初始化的代码。 在 go 语言中,我们可以使用互斥锁(Mutex)来实现这种功能。
# 互斥锁的定义
这里引用一下维基百科的定义:
互斥锁(Mutual exclusion,缩写 Mutex)是一种用于多线程编程中,防止两个线程同时对同一公共资源 (比如全局变量)进行读写的机制。该目的通过将代码切片成一个一个的临界区域(critical section)达成。 临界区域指的是一块对公共资源进行访问的代码,并非一种机制或是算法。
互斥,顾名思义,也就是只有一个线程能持有锁。当然,在 go 中,是只有一个协程能持有锁。
下面是一个简单的例子:
var sum int // 和
var mu sync.Mutex // 互斥锁
// add 将 sum 加 1
func add() {
// 获取锁,只能有一个协程获取到锁,
// 其他协程需要阻塞等待锁释放才能获取到锁。
mu.Lock()
// 临界区域
sum++
mu.Unlock()
}
func TestMutex(t *testing.T) {
// 启动 1000 个协程
var wg sync.WaitGroup
wg.Add(1000)
for i := 0; i < 1000; i++ {
go func() {
// 每个协程里面调用 add()
add()
wg.Done()
}()
}
// 等待所有协程执行完毕
wg.Wait()
// 最终 sum 的值应该是 1000
assert.Equal(t, 1000, sum)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
上面的例子中,我们定义了一个全局变量 sum,用于存储和,然后定义了一个互斥锁 mu, 在 add() 函数中,我们使用 mu.Lock() 来加锁,然后对 sum 进行加 1 操作, 最后使用 mu.Unlock() 来解锁,这样就保证了在任意时刻,只有一个协程能够对 sum 进行加 1 操作, 从而保证了在并发执行 add() 操作的时候 sum 的值是正确的。
上面这个例子,在我之前的文章中已经作为例子出现过很多次了,这里不再赘述了。
# go Mutex 的基本用法
Mutex 我们一般只会用到它的两个方法:
Lock:获取互斥锁。(只会有一个协程可以获取到锁,通常用在临界区开始的地方。)Unlock: 释放互斥锁。(释放获取到的锁,通常用在临界区结束的地方。)
Mutex 的模型可以用下图表示:
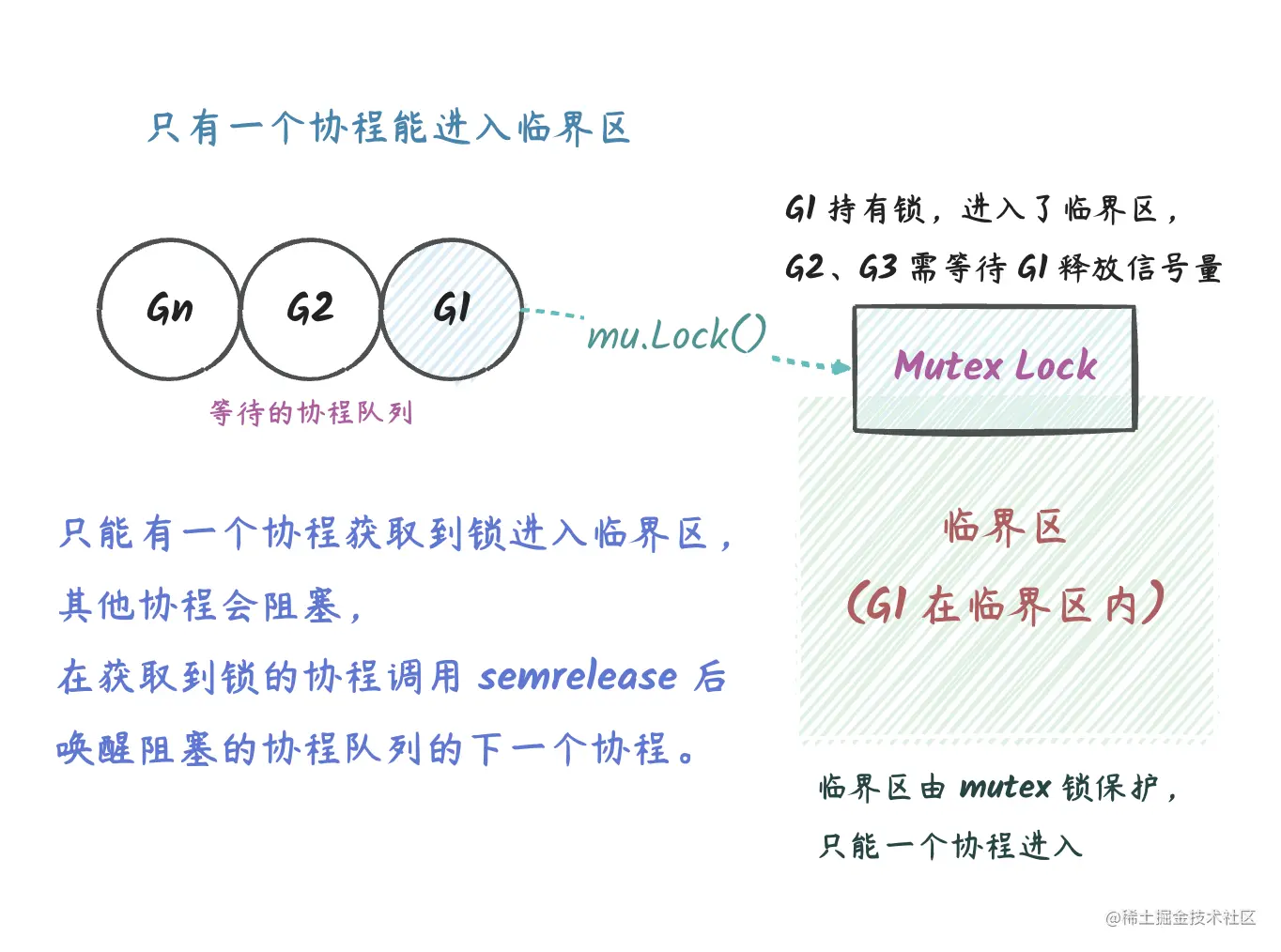
说明:
- 同一时刻只能有一个协程获取到
Mutex的使用权,其他协程需要排队等待(也就是上图的G1->G2->Gn)。 - 拥有锁的协程从临界区退出的时候需要使用
Unlock来释放锁,这个时候等待队列的下一个协程可以获取到锁(实际实现比这里说的复杂很多,后面会细说),从而进入临界区。 - 等待的协程会在
Lock调用处阻塞,Unlock的时候会使得一个等待的协程解除阻塞的状态,得以继续执行。
上面提到的这几点也是
Mutex的基本原理。
# 互斥锁使用的两个例子
了解了 go Mutex 基本原理之后,让我们再来看看 Mutex 的一些使用的例子。
# gin Context 中的 Set 方法
一个很常见的场景就是,并发对 map 进行读写,熟悉 go 的朋友应该知道,go 中的 map 是不支持并发读写的, 如果我们对 map 进行并发读写会导致 panic。
而在 gin 的 Context 结构体中,也有一个 map 类型的字段 Keys,用来在上下文间传递键值对数据, 所以在通过 Set 来设置键值对的时候需要使用 c.mu.Lock() 来先获取互斥锁,然后再对 Keys 做设置。
// Set is used to store a new key/value pair exclusively for this context.
// It also lazy initializes c.Keys if it was not used previously.
func (c *Context) Set(key string, value any) {
// 获取锁
c.mu.Lock()
// 如果 Keys 还没初始化,则进行初始化
if c.Keys == nil {
c.Keys = make(map[string]any)
}
// 设置键值对
c.Keys[key] = value
// 释放锁
c.mu.Unlock()
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
同样的,对 Keys 做读操作的时候也需要使用互斥锁:
// Get returns the value for the given key, ie: (value, true).
// If the value does not exist it returns (nil, false)
func (c *Context) Get(key string) (value any, exists bool) {
// 获取锁
c.mu.RLock()
// 读取 key
value, exists = c.Keys[key]
// 释放锁
c.mu.RUnlock()
return
}
2
3
4
5
6
7
8
9
10
11
可能会有人觉得奇怪,为什么从
map中读也还需要锁。这是因为,如果读的时候没有锁保护, 那么就有可能在Set设置的过程中,同时也在进行读操作,这样就会panic了。
这个例子想要说明的是,像 map 这种数据结构本身就不支持并发读写,我们这种情况下只有使用 Mutex 了。
# sync.Pool 中的 pinSlow 方法
在 sync.Pool 的实现中,有一个全局变量记录了进程内所有的 sync.Pool 对象,那就是 allPools 变量, 另外有一个锁 allPoolsMu 用来保护对 allPools 的读写操作:
var (
// 保护 allPools 和 oldPools 的互斥锁。
allPoolsMu Mutex
// allPools is the set of pools that have non-empty primary
// caches. Protected by either 1) allPoolsMu and pinning or 2)
// STW.
allPools []*Pool
// oldPools is the set of pools that may have non-empty victim
// caches. Protected by STW.
oldPools []*Pool
)
2
3
4
5
6
7
8
9
10
11
12
13
pinSlow 方法中会在 allPoolsMu 的保护下对 allPools 做读写操作:
func (p *Pool) pinSlow() (*poolLocal, int) {
// Retry under the mutex.
// Can not lock the mutex while pinned.
runtime_procUnpin()
allPoolsMu.Lock() // 获取锁
defer allPoolsMu.Unlock() // 函数返回的时候释放锁
pid := runtime_procPin()
// poolCleanup won't be called while we are pinned.
s := p.localSize
l := p.local
if uintptr(pid) < s {
return indexLocal(l, pid), pid
}
if p.local == nil {
allPools = append(allPools, p) // 全局变量修改
}
// If GOMAXPROCS changes between GCs, we re-allocate the array and lose the old one.
size := runtime.GOMAXPROCS(0)
local := make([]poolLocal, size)
atomic.StorePointer(&p.local, unsafe.Pointer(&local[0])) // store-release
runtime_StoreReluintptr(&p.localSize, uintptr(size)) // store-release
return &local[pid], pid
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
这个例子主要是为了说明使用 mu 的另外一种非常常见的场景:并发读写全局变量。
# 互斥锁使用的注意事项
互斥锁如果使用不当,可能会导致死锁或者出现 panic 的情况,下面是一些常见的错误:
- 忘记使用
Unlock释放锁。 Lock之后还没Unlock之前又使用Lock获取锁。也就是重复上锁,go 中的Mutex不可重入。- 死锁:位于临界区内不同的两个协程都想获取对方持有的不同的锁。
- 还没
Lock之前就Unlock。这会导致panic,因为这是没有任何意义的。 - 复制
Mutex,比如将Mutex作为参数传递。
对于第 1 点,我们往往可以使用 defer 关键字来做释放锁的操作。第 2 点不太好发现,只能在开发的时候多加注意。 第 3 点我们在使用锁的时候可以考虑尽量避免在临界区内再去使用别的锁。 最后,Mutex 是不可以复制的,这个可以在编译之前通过 go vet 来做检查。
为什么 Mutex 不能被复制呢?因为 Mutex 中包含了锁的状态,如果复制了,那么这个状态也会被复制, 如果在复制前进行 Lock,复制后进行 Unlock,那就意味着 Lock 和 Unlock 操作的其实是两个不同的状态, 这样显然是不行的,是释放不了锁的。
虽然不可以复制,但是我们可以通过传递指针类型的参数来传递
Mutex。
# 互斥锁锁定的是什么?
在前一篇文章中,我们提到过,原子操作本质上是变量级的互斥锁。而互斥锁本身锁定的又是什么呢? 其实互斥锁本质上是一个信号量,它通过获取释放信号量,最终使得协程获得某一个代码块的执行权力。
也就是说,互斥锁,锁定的是一块代码块。
我们以 go-zero 里面的 collection/fifo.go 为例子说明一下:
// Take takes the first element out of q if not empty.
func (q *Queue) Take() (any, bool) {
// 获取互斥锁(只能有一个协程获取到锁)
q.lock.Lock()
// 函数返回的时候释放互斥锁(获取到锁的协程释放锁之后,其他协程才能进行抢占锁)
defer q.lock.Unlock()
// 下面的代码只有抢占到(也就是互斥锁锁定的代码块)
if q.count == 0 {
return nil, false
}
element := q.elements[q.head]
q.head = (q.head + 1) % len(q.elements)
q.count--
return element, true
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
除了锁定代码块的这一个作用,有另外一个比较关键的地方也是我们不能忽视的, 那就是 互斥锁并不保证临界区内操作的变量不能被其他协程访问。 互斥锁只能保证一段代码只能一个协程执行,但是对于临界区内涉及的共享资源, 你在临界区外也依然是可以对其进行读写的。
我们以上面的代码说明一下:在上面的 Take 函数中,我们对 q.head 和 q.count 都进行了操作, 虽然这些操作代码位于临界区内,但是临界区并不保证持有锁期间其他协程不会在临界区外去修改 q.head 和 q.count。
下面就是一个非常典型的错误的例子:
import (
"fmt"
"sync"
"testing"
)
var mu sync.Mutex
var sum int
// 在锁的保护下对 sum 做读写操作
func test() {
mu.Lock()
sum++
mu.Unlock()
}
func TestMutex(t *testing.T) {
var wg sync.WaitGroup
wg.Add(1000)
for i := 0; i < 500; i++ {
go func() {
test()
wg.Done()
}()
// 位于临界区外,也依然是可以对 sum 做读写操作的。
sum++
}
wg.Wait()
fmt.Println(sum)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
靠谱的做法是,对于有共享资源的读写的操作都使用
Mutex保护起来。
当然,如果我们只有一个变量,那么可能使用原子操作就足够了。
# 互斥锁实现原理
互斥锁的实现有以下几个关键的地方:
- 信号量:这是操作系统中的同步对象。
- 等待队列:获取不到互斥锁的协程,会放入到一个先入先出队列的队列尾部。这样信号量释放的时候,可以依次对它们唤醒。
- 原子操作:互斥锁的实现中,使用了一个字段来记录了几种不同的状态,使用原子操作可以保证几种状态可以一次性变更完成。
我们先来看看 Mutex结构体定义:
type Mutex struct {
state int32 // 状态字段
sema uint32 // 信号量
}
2
3
4
其中 state 字段记录了四种不同的信息:
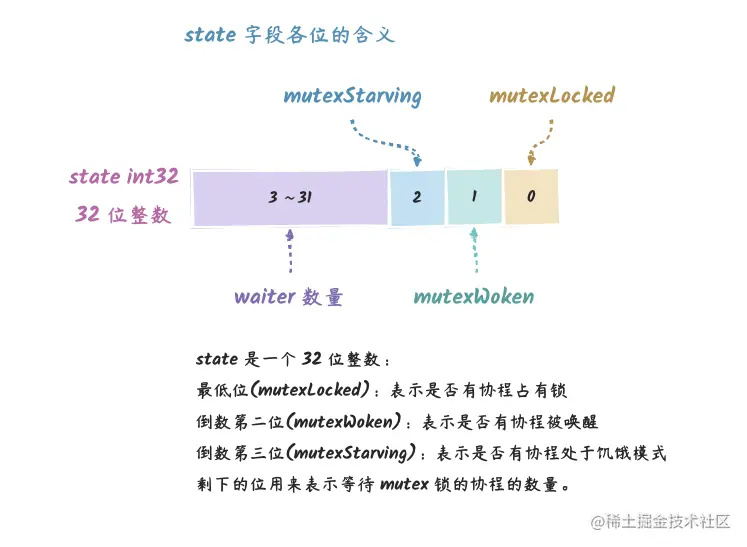
这四种不同信息在源码中定义了不同的常量:
const (
mutexLocked = 1 << iota // 表示有 goroutine 拥有锁
mutexWoken // 唤醒(就是第 2 位)
mutexStarving // 饥饿(第 3 位)
mutexWaiterShift = iota // 表示第 4 位开始,表示等待者的数量
starvationThresholdNs = 1e6 // 1ms 进入饥饿模式的等待时间阈值
)
2
3
4
5
6
7
8
而 sema 的含义比较简单,就是一个用作不同 goroutine 同步的信号量。
# 信号量
go 的 Mutex 是基于信号量来实现的,那信号量又是什么呢?
维基百科:信号量是一个同步对象,用于保持在
0至指定最大值之间的一个计数值。当线程完成一次对该semaphore对象的等待(wait)时,该计数值减一;当线程完成一次对semaphore对象的释放(release)时,计数值加一。
上面这个解释有点难懂,通俗地说,就是一个数字,调用 wait 的时候,这个数字减去 1,调用 release 的时候,这个数字加上 1。 (还有一个隐含的逻辑是,如果这个数小于 0,那么调用 wait 的时候会阻塞,直到它大于 0。)
对应到 go 的 Mutex 中,有两个操作信号量的函数:
runtime_Semrelease: 自动递增信号量并通知等待的 goroutine。runtime_SemacquireMutex: 是一直等到信号量大于 0,然后自动递减。
我们注意到了,其实 runtime_SemacquireMutex 是有一个前提条件的,那就是等到信号量大于 0。 其实信号量的两个操作 P/V 就是一个加 1 一个减 1,所以在实际使用的时候,也是需要一个获取锁的操作对应一个释放锁的操作, 否则,其他协程都无法获取到锁,因为信号量一直不满足。
# 等待队列
go 中如果已经有 goroutine 持有互斥锁,那么其他的协程会放入一个 FIFO 队列中,如下图:
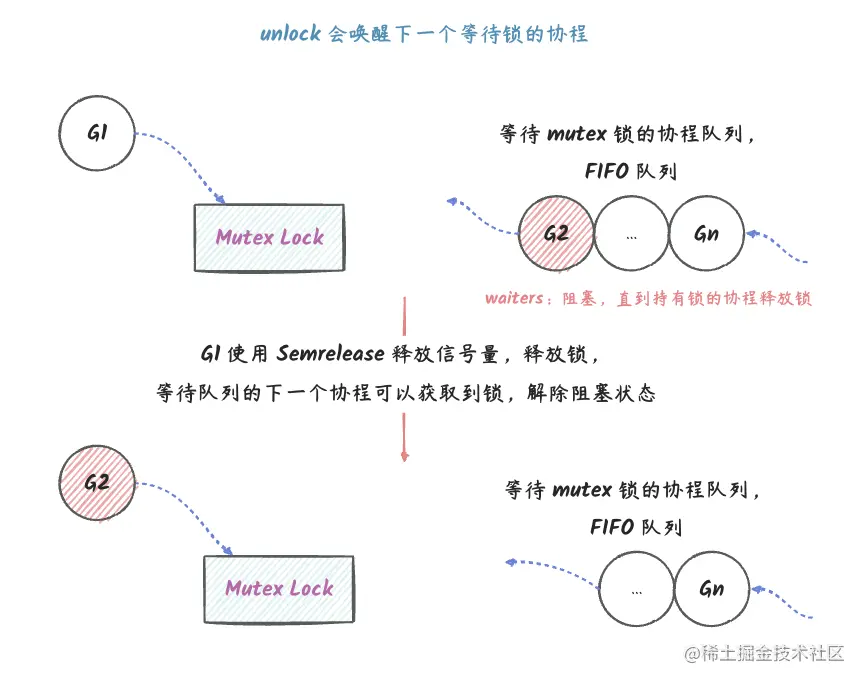
说明:
G1表示持有互斥锁的 goroutine,G2...Gn表示一个 goroutine 的等待队列,这是一个先入先出的队列。G1先持有锁,得以进入临界区,其他想抢占锁的 goroutine 阻塞在Lock调用处。G1在使用完锁后,会使用Unlock来释放锁,本质上是释放了信号量,然后会唤醒FIFO队列头部的goroutine。G2从FIFO队列中移除,进入临界区。G2使用完锁之后也会使用Unlock来释放锁。
上面只是一个大概模型,在实际实现中,比这个复杂很多倍,下面会继续深入讲解。
# 原子操作
go 的 Mutex 实现中,state 字段是一个 32 位的整数,不同的位记录了四种不同信息,在这种情况下, 只需要通过原子操作就可以保证一次性实现对四种不同状态信息的更改,而不需要更多额外的同步机制。
但是毋庸置疑,这种实现会大大降低代码的可读性,因为通过一个整数来记录不同的信息, 就意味着,需要通过各种位运算来实现对这个整数不同位的修改,比如将上锁的操作:
new |= mutexLocked
当然,这只是 Mutex 实现中最简单的一种位运算了。下面以 state 记录的四种不同信息为维度来具体讲解一下:
mutexLocked1:这是
state1的最低位,
11表示锁被占用,
01表示锁没有被占用。
new := mutexLocked新状态为上锁状态
mutexWoken1: 这是表示是否有协程被唤醒了的状态
new = (old - 1<<mutexWaiterShift) | mutexWoken等待者数量减去 1 的同时,设置唤醒标识new &^= mutexWoken清除唤醒标识
mutexStarving1:饥饿模式的标识
new |= mutexStarving设置饥饿标识
等待者数量:
state >> mutexWaiterShift1就是等待者的数量,也就是上面提到的
FIFO1队列中 goroutine 的数量
new += 1 << mutexWaiterShift等待者数量加 1delta := int32(mutexLocked - 1<<mutexWaiterShift)上锁的同时,将等待者数量减 1
这里并没有涵盖
Mutex中所有的位运算,其他操作在下文讲解源码实现的时候会提到。
在上面做了这一系列的位运算之后,我们会得到一个新的 state 状态,假设名为 new,那么我们就可以通过 CAS 操作来将 Mutex 的 state 字段更新:
atomic.CompareAndSwapInt32(&m.state, old, new)
通过上面这个原子操作,我们就可以一次性地更新 Mutex 的 state 字段,也就是一次性更新了四种状态信息。
这种通过一个整数记录不同状态的写法在
sync包其他的一些地方也有用到,比如WaitGroup中的state字段。
最后,对于这种操作,我们需要注意的是,因为我们在执行 CAS 前后是没有其他什么锁或者其他的保护机制的, 这也就意味着上面的这个 CAS 操作是有可能会失败的,那如果失败了怎么办呢?
如果失败了,也就意味着肯定有另外一个 goroutine 率先执行了 CAS 操作并且成功了,将 state 修改为了一个新的值。 这个时候,其实我们前面做的一系列位运算得到的结果实际上已经不对了,在这种情况下,我们需要获取最新的 state,然后再次计算得到一个新的 state。
所以我们会在源码里面看到 CAS 操作是写在 for 循环里面的。
# Mutex 的公平性
在前面,我们提到 goroutien 获取不到锁的时候,会进入一个 FIFO 队列的队列尾,在实际实现中,其实没有那么简单, 为了获得更好的性能,在实现的时候会尽量先让运行状态的 goroutine 获得锁,当然如果队列中的 goroutine 等待太久(大于 1ms), 那么就会先让队列中的 goroutine 获得锁。
下面是文档中的说明:
Mutex 可以处于两种操作模式:正常模式和饥饿模式。在正常模式下,等待者按照FIFO(先进先出)的顺序排队,但是被唤醒的等待者不拥有互斥锁,会与新到达的 Goroutine 竞争所有权。新到达的 Goroutine 有优势——它们已经在 CPU 上运行,数量可能很多,因此被唤醒的等待者有很大的机会失去锁。在这种情况下,它将排在等待队列的前面。如果等待者未能在1毫秒内获取到互斥锁,则将互斥锁切换到饥饿模式。 在饥饿模式下,互斥锁的所有权直接从解锁 Goroutine 移交给队列前面的等待者。新到达的 Goroutine 即使看起来未被锁定,也不会尝试获取互斥锁,也不会尝试自旋。相反,它们会将自己排队在等待队列的末尾。如果等待者获得互斥锁的所有权并发现(1)它是队列中的最后一个等待者,或者(2)它等待时间少于1毫秒,则将互斥锁切换回正常模式。 正常模式的性能要优于饥饿模式,因为 Goroutine 可以连续多次获取互斥锁,即使有被阻塞的等待者。饥饿模式很重要,可以防止尾部延迟的病态情况。
简单总结:
Mutex有两种模式:正常模式、饥饿模式。- 正常模式下:
- 被唤醒的 goroutine 和正在运行的 goroutine 竞争锁。这样可以运行中的协程有机会先获取到锁,从而避免了协程切换的开销。性能更好。
- 饥饿模式下:
- 优先让队列中的 goroutine 获得锁,并且直接放弃时间片,让给队列中的 goroutine,运行中的 goroutine 想获取锁要到队尾排队。更加公平。
# Mutex 源码剖析
Mutex 本身的源码其实很少,但是复杂程度是非常高的,所以第一次看的时候可能会非常懵逼,但是不妨碍我们去了解它的大概实现原理。
Mutex 中主要有两个方法,Lock 和 Unlock,使用起来非常的简单,但是它的实现可不简单。下面我们就来深入了解一下它的实现。
# Lock
Lock 方法的实现如下:
// Lock 获取锁。
// 如果锁已在使用中,则调用 goroutine 将阻塞,直到互斥量可用。
func (m *Mutex) Lock() {
// Fast path: grab unlocked mutex.
// 上锁成功则直接返回
if atomic.CompareAndSwapInt32(&m.state, 0, mutexLocked) {
return
}
// Slow path (outlined so that the fast path can be inlined)
// 没有上锁成功,这个时候需要做的事情就有点多了。
m.lockSlow()
}
2
3
4
5
6
7
8
9
10
11
12
13
在 Lock 方法中,第一次获取锁的时候是非常简单的,一个简单的原子操作设置一下 mutexLocked 标识就完成了。 但是如果这个原子操作失败了,表示有其他 goroutine 先获取到了锁,这个时候就需要调用 lockSlow 来做一些额外的操作了:
// 获取 mutex 锁
func (m *Mutex) lockSlow() {
var waitStartTime int64 // 当前协程开始等待的时间
starving := false // 当前协程是否是饥饿模式
awoke := false // 唤醒标志(是否当前协程就是被唤醒的协程)
iter := 0 // 自旋次数(超过一定次数如果还没能获得锁,就进入等待)
old := m.state // 旧的状态,每次 for 循环会重新获取当前的状态字段
for {
// 自旋:目的是让正在运行中的 goroutine 尽快获取到锁。
// 两种情况不会自旋:
// 1. 饥饿模式:在饥饿模式下,锁会直接交给等待队列中的 goroutine,所以不会自旋。
// 2. 锁被释放了:另外如果运行到这里的时候,发现锁已经被释放了,也就不需要自旋了。
if old&(mutexLocked|mutexStarving) == mutexLocked && runtime_canSpin(iter) {
// 设置 mutexWoken 标识
// 如果自旋是有意义的,则会进入到这里,尝试设置 mutexWoken 标识。
// 设置成功在持有锁的 goroutine 获取锁的时候不会唤醒等待队列中的 goroutine,下一个获取锁的就是当前 goroutine。
if !awoke && old&mutexWoken == 0 && old>>mutexWaiterShift != 0 &&
atomic.CompareAndSwapInt32(&m.state, old, old|mutexWoken) {
// 各个判断的含义:
// !awoke 已经被唤醒过一次了,说明当前协程是被从等待队列中唤醒的协程/又或者已经成功设置 mutexWoken 标识了,不需要再唤醒了。
// old&mutexWoken == 0 如果不等于 0 说明有 goroutine 被唤醒了,不会尝试设置 mutexWoken 标识
// old>>mutexWaiterShift != 0 如果等待队列为空,当前 goroutine 就是下一个抢占锁的 goroutine
// 前面的判断都通过了,才会进行 CAS 操作尝试设置 mutexWoken 标识
awoke = true
}
runtime_doSpin() // 自旋
iter++ // 自旋次数 +1(超过一定次数会停止自旋)
old = m.state // 再次获取锁的最新状态,之后会检查是否锁被释放了
continue // 继续下一次检查
}
new := old
// 饥饿模式下,新到达的 goroutines 必须排队。
// 不是饥饿状态,直接竞争锁。
if old&mutexStarving == 0 {
new |= mutexLocked
}
// 进入等待队列的两种情况:
// 1. 锁依然被占用。
// 2. 进入了饥饿模式。
if old&(mutexLocked|mutexStarving) != 0 {
new += 1 << mutexWaiterShift // 等待者数量 +1
}
// 已经等待超过了 1ms,且锁被其他协程占用,则进入饥饿模式
if starving && old&mutexLocked != 0 {
new |= mutexStarving
}
// 唤醒之后,需要重置唤醒标志。
// 不管有没有获取到锁,都是要清除这个标识的:
// 获取到锁肯定要清除,如果获取到锁,需要让其他运行中的 goroutine 来抢占锁;
// 如果没有获取到锁,goroutine 会阻塞,这个时候是需要持有锁的 goroutine 来唤醒的,如果有 mutexWoken 标识,持有锁的 goroutine 唤醒不了。
if awoke {
if new&mutexWoken == 0 {
throw("sync: inconsistent mutex state")
}
new &^= mutexWoken // 重置唤醒标志
}
// 成功设置新状态
if atomic.CompareAndSwapInt32(&m.state, old, new) {
// 原来锁的状态已释放,并且不是饥饿状态,正常请求到了锁,返回
if old&(mutexLocked|mutexStarving) == 0 { // 这意味着当前的 goroutine 成功获取了锁
break
}
// 如果已经被唤醒过,会被加入到等待队列头。
queueLifo := waitStartTime != 0
if waitStartTime == 0 {
waitStartTime = runtime_nanotime()
}
// 阻塞等待
// queueLifo 为 true,表示加入到队列头。否则,加入到队列尾。
// (首次加入队列加入到队尾,不是首次加入则加入队头,这样等待最久的 goroutine 优先能够获取到锁。)
runtime_SemacquireMutex(&m.sema, queueLifo, 1)
// 从等待队列中唤醒,检查锁是否应该进入饥饿模式。
starving = starving || runtime_nanotime()-waitStartTime > starvationThresholdNs
// 获取当前的锁最新状态
old = m.state
// 如果锁已经处于饥饿状态,直接抢到锁,返回。
// 饥饿模式下,被唤醒的协程可以直接获取到锁。
// 新来的 goroutine 都需要进入队列等待。
if old&mutexStarving != 0 {
// 如果这个 goroutine 被唤醒并且 Mutex 处于饥饿模式,P 的所有权已经移交给我们,
// 但 Mutex 处于不一致的状态:mutexLocked 未设置,我们仍然被视为等待者。修复这个问题。
if old&(mutexLocked|mutexWoken) != 0 || old>>mutexWaiterShift == 0 {
throw("sync: inconsistent mutex state")
}
// 加锁,并且减少等待者数量。
// 实际上是两步操作合成了一步:
// 1. m.state = m.state + 1 (获取锁)
// 2. m.state = m.state - 1<<mutexWaiterShift(waiter - 1)
delta := int32(mutexLocked - 1<<mutexWaiterShift)
// 清除饥饿状态的两种情况:
// 1. 如果不需要进入饥饿模式(当前被唤醒的 goroutine 的等待时间小于 1ms)
// 2. 原来的等待者数量为 1,说明是最后一个被唤醒的 goroutine。
if !starving || old>>mutexWaiterShift == 1 {
// 退出饥饿模式
delta -= mutexStarving
}
// 原子操作,设置新状态。
atomic.AddInt32(&m.state, delta)
break
}
// 设置唤醒标记,重新抢占锁(会与那些运行中的 goroutine 一起竞争锁)
awoke = true
iter = 0
} else {
// CAS 更新状态失败,获取最新状态,然后重试
old = m.state
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
我们可以看到,lockSlow 的处理非常的复杂,又要考虑让运行中的 goroutine 尽快获取到锁,又要考虑不能让等待队列中的 goroutine 等待太久。
代码中注释很多,再简单总结一下其中的流程:
- 为了让循环中的 goroutine 可以先获取到锁,会先让 goroutine 自旋等待锁的释放,这是因为运行中的 goroutine 正在占用 CPU,让它先获取到锁可以避免一些不必要的协程切换,从而获得更好的性能。
- 自旋完毕之后,会尝试获取锁,同时也要根据旧的锁状态来更新锁的不同状态信息,比如是否进入饥饿模式等。
- 计算得到一个新的
state后,会进行CAS操作尝试更新state状态。 CAS失败会重试上面的流程。CAS成功之后会做如下操作:
- 判断当前是否已经获取到锁,如果是,则返回,
Lock成功了。 - 会判断当前的 goroutine 是否是已经被唤醒过,如果是,会将当前 goroutine 加入到等待队列头部。
- 调用
runtime_SemacquireMutex,进入阻塞状态,等待下一次唤醒。 - 唤醒之后,判断是否需要进入饥饿模式。
- 最后,如果已经是饥饿模式,当前 goroutine 直接获取到锁,退出循环,否则,再进行下一次抢占锁的循环中。
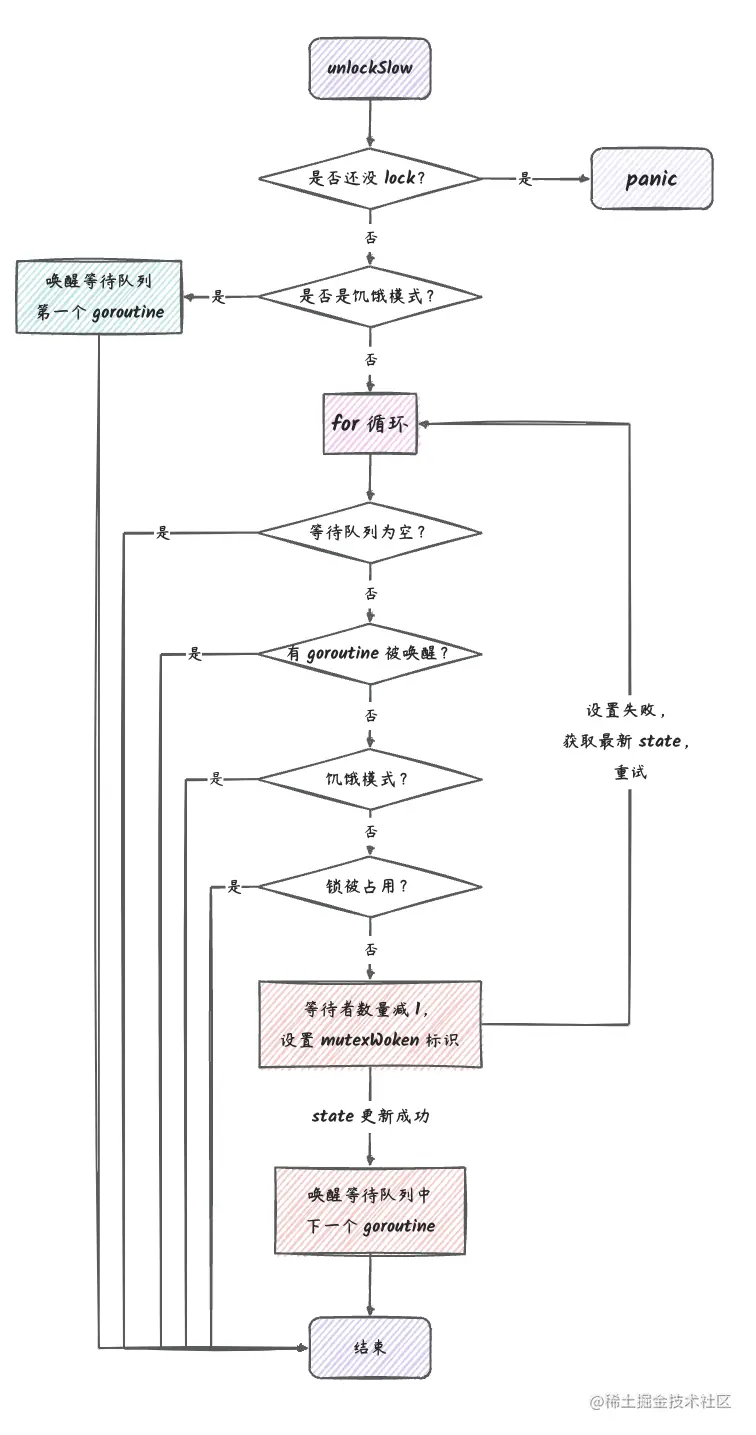
具体流程我们可以参考一下下面的流程图:
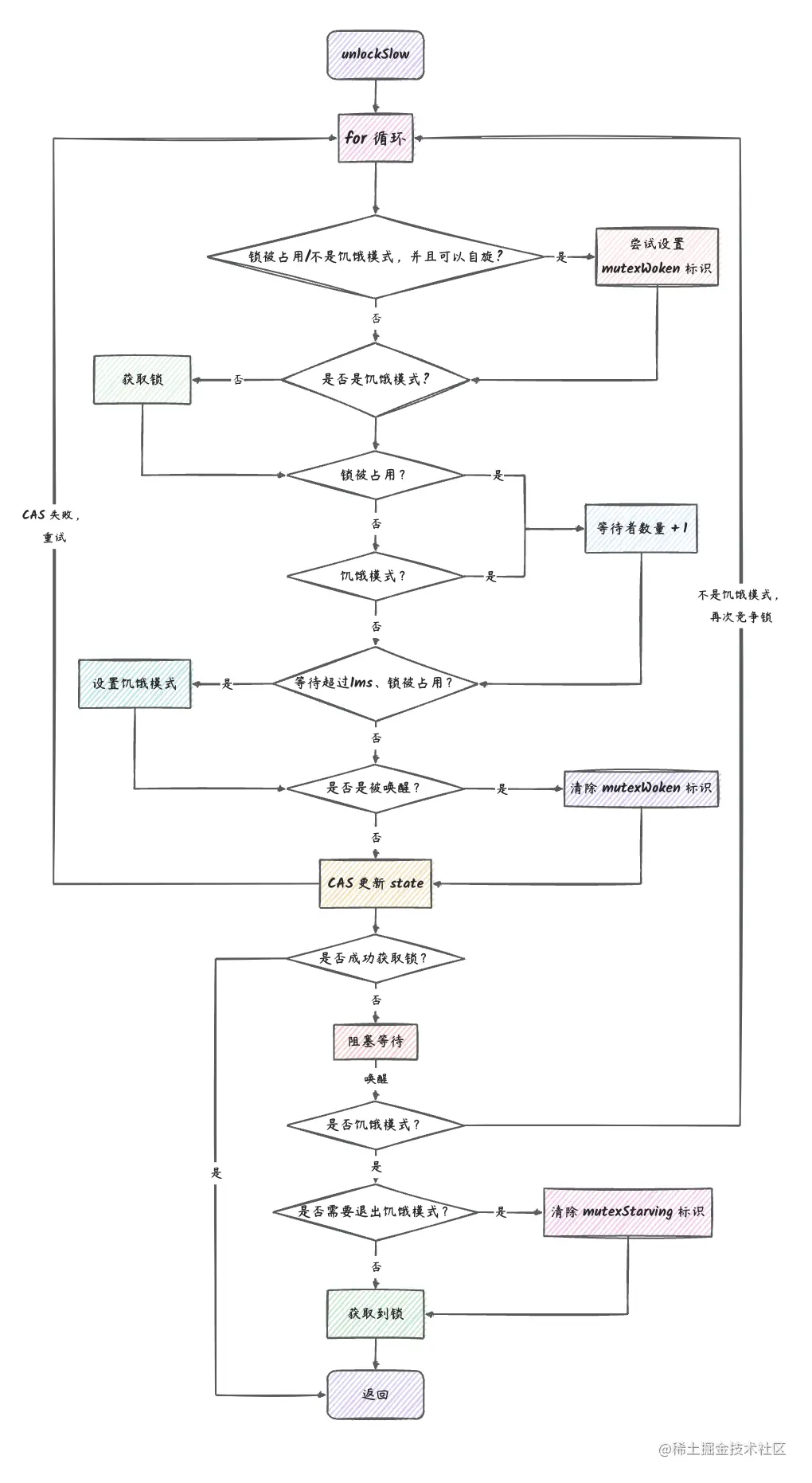
图中有一些矩形方框描述了
unlockSlow的关键流程。
# Unlock
Unlock 方法的实现如下:
// Unlock 释放互斥锁。
// 如果 m 在进入 Unlock 时未被锁定,则会出现运行时错误。
func (m *Mutex) Unlock() {
// Fast path: drop lock bit.
// unlock 成功
// unLock 操作实际上是将 state 减去 1。
new := atomic.AddInt32(&m.state, -mutexLocked)
if new != 0 { // 等待队列为空的时候直接返回了
// 唤醒一个等待锁的 goroutine
m.unlockSlow(new)
}
}
2
3
4
5
6
7
8
9
10
11
12
Unlock 做了两件事:
- 释放当前 goroutine 持有的互斥锁:也就是将
state减去 1 - 唤醒等待队列中的下一个 goroutine
如果只有一个 goroutine 在使用锁,只需要简单地释放锁就可以了。 但是如果有其他的 goroutine 在阻塞等待,那么持有互斥锁的 goroutine 就有义务去唤醒下一个 goroutine。
唤醒的流程相对复杂一些:
// unlockSlow 唤醒下一个等待锁的协程。
func (m *Mutex) unlockSlow(new int32) {
// 如果未加锁,则会抛出错误。
if (new+mutexLocked)&mutexLocked == 0 {
fatal("sync: unlock of unlocked mutex")
}
// 下面的操作是唤醒一个在等待锁的协程。
// 存在两种情况:
// 1. 正常模式:
// a. 不需要唤醒:没有等待者、锁已经被抢占、有其他运行中的协程在尝试获取锁、已经进入了饥饿模式
// b. 需要唤醒:其他情况
// 2. 饥饿模式:唤醒等待队列头部的那个协程
if new&mutexStarving == 0 {
// 不是饥饿模式
old := new
// 自旋
for {
// 下面几种情况不需要唤醒:
// 1. 没有等待者了(没得唤醒)
// 2. 锁已经被占用(只能有一个 goroutine 持有锁)
// 3. 有其他运行中的协程已经被唤醒(运行中的 goroutine 通过自旋先抢占到了锁)
// 4. 饥饿模式(饥饿模式下,所有新的 goroutine 都要排队,饥饿模式会直接唤醒等待队列头部的 gorutine)
if old>>mutexWaiterShift == 0 || old&(mutexLocked|mutexWoken|mutexStarving) != 0 {
return
}
// 获取到唤醒等待者的权力,开始唤醒一个等待者。
// 下面这一行实际上是两个操作:
// 1. waiter 数量 - 1
// 2. 设置 mutexWoken 标志
new = (old - 1<<mutexWaiterShift) | mutexWoken
if atomic.CompareAndSwapInt32(&m.state, old, new) {
// 正常模式下唤醒了一个 goroutine
//(第二个参数为 false,表示当前的 goroutine 在释放信号量后还会继续执行直到用完时间片)
runtime_Semrelease(&m.sema, false, 1)
return
}
// 唤醒失败,进行下一次尝试。
old = m.state
}
} else {
// 饥饿模式:将互斥锁的所有权移交给下一个等待者,并放弃我们的时间片,以便下一个等待者可以立即开始运行。
// 注意:如果“mutexLocked”未设置,等待者在唤醒后会将其设置。
// 但是,如果设置了“mutexStarving”,则仍然认为互斥锁已被锁定,因此新到来的goroutine不会获取它。
//
// 当前的 goroutine 放弃 CPU 时间片,让给阻塞在 sema 的 goroutine。
runtime_Semrelease(&m.sema, true, 1)
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
unlockSlow 逻辑相比 lockSlow 要简单许多,我们可以再结合下面的流程图来阅读上面的源码:
# runtime_Semrelease 第二个参数的含义
细心的朋友可能注意到了,在 unlockSlow 的实现中,有两处地方调用了 runtime_Semrelease 这个方法, 这个方法的作用是释放一个信号量,这样可以让阻塞在信号量上的 goroutine 得以继续执行。 它的第一个参数我们都知道,是信号量,而第二个参数 true 和 false 分别传递了一次, 那么 true 和 false 分别有什么作用呢?
答案是,设置为 true 的时候,当前的 goroutine 会直接放弃自己的时间片, 将 P 的使用权交给 Mutex 等待队列中的第一个 goroutine, 这样的目的是,让 Mutex 等待队列中的 goroutine 可以尽快地获取到锁。
# 总结
互斥锁在并发编程中也算是非常常见的一种操作了,使用互斥锁可以限制只有一个 goroutine 可以进入临界区, 这对于并发修改全局变量、初始化等情况非常好用。最后,再总结一下本文所讲述的内容:
互斥锁是一种用于多线程编程中,防止两个线程同时对同一公共资源进行读写的机制。go 中的互斥锁实现是
sync.Mutex。Mutex1的操作只有两个:
Lock获取锁,同一时刻只能有一个 goroutine 可以获取到锁,其他 goroutine 会先通过自旋抢占锁,抢不到则阻塞等待。Unlock释放锁,释放锁之前必须有 goroutine 持有锁。释放锁之后,会唤醒等待队列中的下一个 goroutine。
Mutex1常见的使用场景有两个:
- 并发读写
map:如gin中Context的Keys属性的读写。 - 并发读写全局变量:如
sync.Pool中对allPools的读写。
- 并发读写
使用
Mutex1需要注意以下几点:
- 不要忘记使用
Unlock释放锁 Lock之后,没有释放锁之前,不能再次使用Lock- 注意不同 goroutine 竞争不同锁的情况,需要考虑一下是否有可能会死锁
- 在
Unlock之前,必须已经调用了Lock,否则会panic - 在第一次使用
Mutex之后,不能复制,因为这样一来Mutex的状态也会被复制。这个可以使用go vet来检查。
- 不要忘记使用
互斥锁可以保护一块代码块只能有一个 goroutine 执行,但是不保证临界区内操作的变量不被其他 goroutine 做并发读写操作。
go 的
Mutex1基于以下技术实现:
- 信号量:这是操作系统层面的同步机制
- 队列:在 goroutine 获取不到锁的时候,会将这些 goroutine 放入一个 FIFO 队列中,下次唤醒会唤醒队列头的 goroutine
- 原子操作:
state字段记录了四种不同的信息,通过原子操作就可以保证数据的完整性
go
Mutex1的公平性:
- 正在运行的 goroutine 如果需要锁的话,尽量让它先获取到锁,可以避免不必要的协程上下文切换。会和被唤醒的 goroutine 一起竞争锁。
- 但是如果等待队列中的 goroutine 超过了 1ms 还没有获取到锁,那么会进入饥饿模式
go
Mutex1的两种模式:
- 正常模式:运行中的 goroutine 有一定机会比等待队列中的 goroutine 先获取到锁,这种模式有更好的性能。
- 饥饿模式:所有后来的 goroutine 都直接进入等待队列,会依次从等待队列头唤醒 goroutine。可以有效避免尾延迟。
饥饿模式下,
Unlock的时候会直接将当前 goroutine 所在 P 的使用权交给等待队列头部的 goroutine,放弃原本属于自己的时间片。